2021. 3. 5. 17:13ㆍ머신러닝/Kaggle
이전 글:
[Kaggle] (Titanic)타이타닉 생존자 예측(1) (tistory.com)
[Kaggle] (Titanic)타이타닉 생존자 예측(1)
Titanic: Machine Learning from Disaster 캐글 입문으로 가장 많이 사용되는 타이타닉 문제를 풀어보았다. 해당 문제는 아래 링크에서 찾아 볼 수 있습니다. Titanic - Machine Learning from Disaster | Kaggle..
shinejay.tistory.com
Pclass와 Sex, Survived의 관계에 대해 알아봤다.
이번엔 Pclass, Age, Sex와 Survived의 관계를 알아보자.
f,ax = plt.subplots(1,2,figsize=(20,10))
sns.violinplot('Pclass','Age',hue='Survived', data = train, split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex','Age',hue='Survived',split=True,data = train, ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110),10)
plt.show()
나이가 어릴수록 생존율이 훨씬 높다.
Age의 결측치가 171개나 되는데, 임의의 숫자를 집어넣기에는 예측에 큰 영향을 줄 것이다.
그렇다면 결측치를 어떤 방법으로 채워야 할까?
Initial
영어 이름에는 Initial이 존재한다.(명칭이 맞는 지는 모르겠습니다 ㅎㅎ...)
예를 들면 Mr.ooo, Mrs.ooo, Ms.ooo 등의 다양한 호칭들이 존재하는데 이걸 한 번 이름에서 뽑아내보자.
train['Initial']=0
for i in train:
train['Initial'] = train.Name.str.extract('([A-Za-z]+)\.')
test['Initial']=0
for i in test:
test['Initial'] = test.Name.str.extract('([A-Za-z]+)\.')Initial을 분류해서 train과 test 데이터셋에 넣어준다.
train['Initial'].head(10)
대충 이런 결과가 나온다.
train['Initial'].value_counts()
test['Initial'].value_counts()값들의 count를 확인하면

이렇게 Mr, Mrs, Miss 이외에 Master, Col, Rev 등 다양한 Initial들이 나온다.
(상기의 캡쳐는 test셋 결과입니다. train셋은 다른 Initial들이 더 있을 수 있습니다.)
한 두개씩 있는 것들을 하나하나 다 처리하면 예측의 정확도가 떨어질 수 있으므로 나이와 성별을 파악해 Mr, Miss, Mrs, Other(그 외 기타)등으로 변경해준다.
train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mrs','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'], inplace = True)
test['Initial'].replace(['Rev','Col','Dr','Dona','Ms'],['Other','Other','Mr','Mr',"Miss"],inplace=True)위와 같이 대치하였는데, 이 내용은 아래 링크의 노트북을 참고했다.(In[14]~[16]) 참고)
EDA To Prediction(DieTanic) | Kaggle
EDA To Prediction(DieTanic)
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
Initial은 나이의 결측치를 예측하는데 큰 도움이 된다.
train.groupby('Initial')['Age'].mean()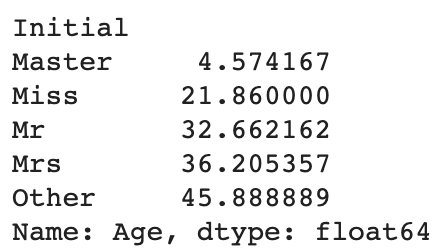
보다시피 Initial에 따라 나이가 분명히 차이가 나는 것을 알 수 있다.
Age의 결측치는 위 내용에 따라 채워준다.
train.loc[(train.Age.isnull())&(train.Initial=='Mr'),'Age']=33
train.loc[(train.Age.isnull())&(train.Initial=='Mrs'),'Age']=36
train.loc[(train.Age.isnull())&(train.Initial=='Master'),'Age']=5
train.loc[(train.Age.isnull())&(train.Initial=='Miss'),'Age']=22
train.loc[(train.Age.isnull())&(train.Initial=='Other'),'Age']=46
test.loc[(train.Age.isnull())&(test.Initial=='Mr'),'Age']=33
test.loc[(train.Age.isnull())&(test.Initial=='Mrs'),'Age']=36
test.loc[(train.Age.isnull())&(test.Initial=='Master'),'Age']=5
test.loc[(train.Age.isnull())&(test.Initial=='Miss'),'Age']=22
test.loc[(train.Age.isnull())&(test.Initial=='Other'),'Age']=46train.Age.isnull().any(),test.Age.isnull().any()남은 결측치가 있는 지 확인 해 보면 False가 나오는 것을 볼 수 있을 것이다.
Age
Age의 결측치를 다 채웠으니 Age와 Survived의 관계에 대해서 알아보자.
f,ax=plt.subplots(1,2,figsize=(20,10))
train[train['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived=0')
x1=list(range(0,85,5))
ax[0].set_xticks(x1)
train[train['Survived']==1].Age.plot.hist(ax=ax[1],color='green',bins=20,edgecolor='black')
ax[1].set_title('Survived=1')
x2=list(range(0,85,5))
ax[1].set_xticks(x2)
plt.show()
0~5세의 아이들과 20~25세 사람들의 생존율이 높고 30~35세의 사람들이 가장 많이 사망했다.
sns.factorplot('Pclass','Survived',col='Initial',data=train)
plt.show()
Initial과 Pclass,Survived를 비교해보자.
여성(Mrs, Miss) 아이(Master)의 생존율이 매우 높다. 1,2에서는 거의 1.0에 가깝고 3에서도 남성(Mr)보다는 훨씬 높다.
pd.crosstab([train.Embarked,train.Pclass],[train.Sex,train.Survived],margins=True).style.background_gradient(cmap='summer_r')
Crosstab으로 보면 위와 같이 실제로 1,2 Pclass의 여성은 사망자가 거의 없다.
sns.factorplot('Embarked','Survived',data = train)
fig = plt.gcf()
fig.set_size_inches(5,3)
plt.show()
C에서 embarked 한 경우의 생존율이 가장 높다. 그 이유를 알아보기 위해 여러 지표들과 함께 embarked를 비교해보자.
f,ax = plt.subplots(2,2,figsize=(20,15))
sns.countplot('Embarked',data=train,ax=ax[0,0])
ax[0,0].set_title('# of passengers Boarded')
sns.countplot('Embarked',hue='Sex', data = train, ax=ax[0,1])
ax[0,1].set_title('Male-Female split for Embarked')
sns.countplot('Embarked',hue='Survived',data=train,ax=ax[1,0])
ax[1,0].set_title('Embarked vs Survived')
sns.countplot('Embarked',hue='Pclass',data = train, ax=ax[1,1])
ax[1,1].set_title('Embarked vs Pclass')
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()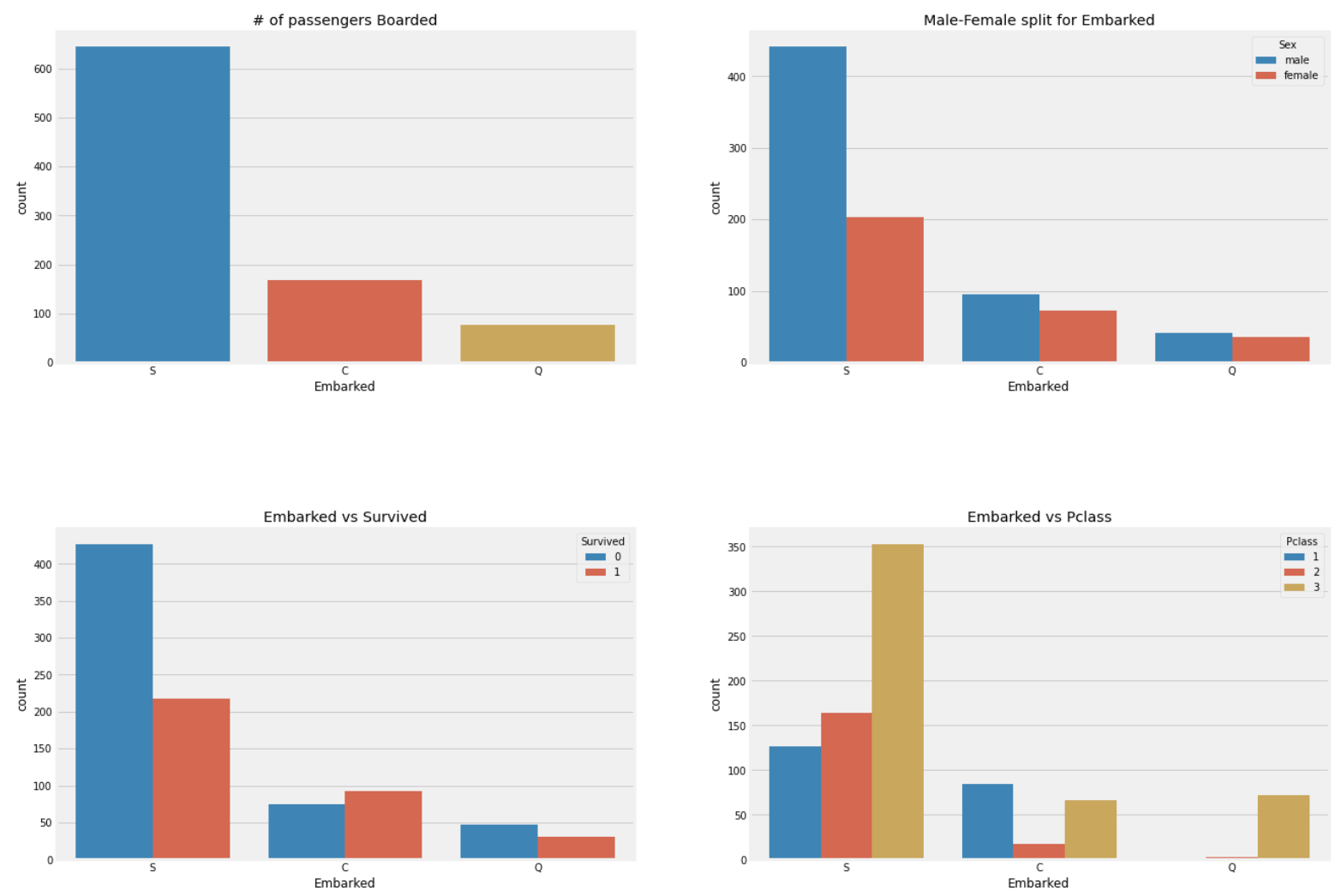
S: 가장 많이 탑승했고, 3class의 비율이 가장 높다.
C: 1class의 비율이 가장 높으며, 여성의 비율도 S보다 훨씬 높다(Q보단 낮음).
Q: 여성의 비율은 가장 높지만 3class가 대부분을 차지한다.
sns.factorplot('Pclass','Survived',hue = 'Sex', col = 'Embarked',data = train)
plt.show()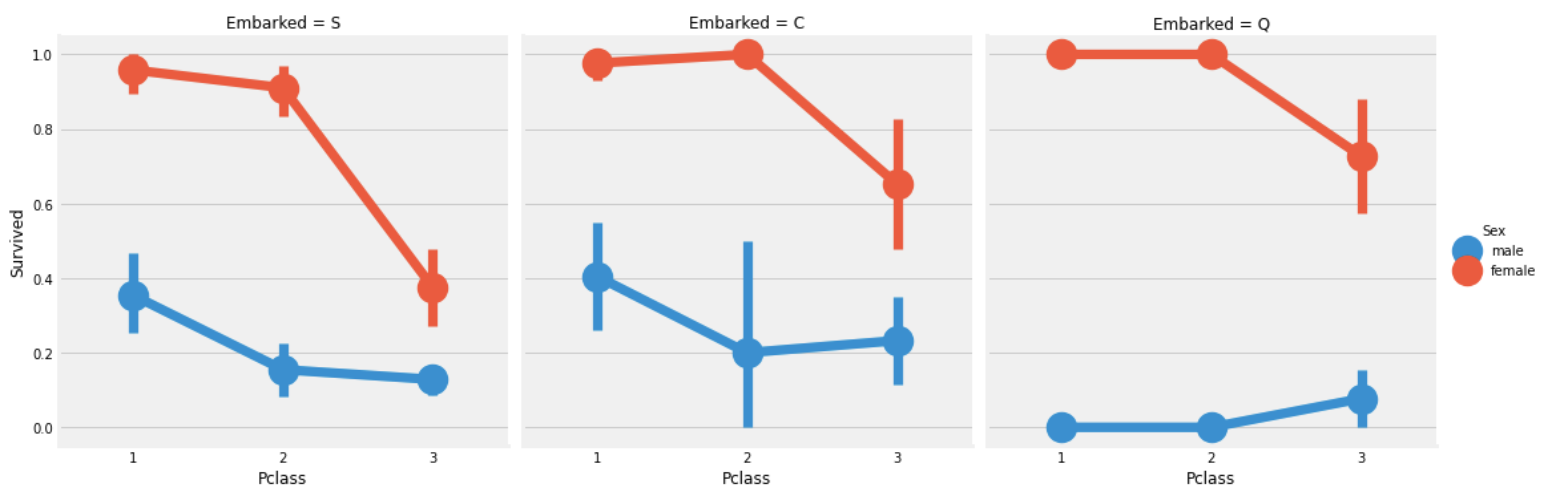
1,2 class에서의 여성의 생존율은 embarked와 무관하게 매우 높고 S 에서의 3class는 남녀 모두 생존율이 상대적으로 낮다.
train['Embarked'].fillna('S',inplace=True)
test['Embarked'].fillna('S',inplace=True)Embarked에도 결측치가 존재하는데, 대부분의 승객이 S포트에서 왔으므로 결측치는 S로 채워준다.
오늘은 여기까지,,,
다음 글에서는 SibSp부터 시작하겠습니다.
'머신러닝 > Kaggle' 카테고리의 다른 글
| [Kaggle] (Titanic)타이타닉 생존자 예측(1) (0) | 2021.02.28 |
|---|